死党暗恋校花失败,我爬了这个网站发给他分分钟治愈,男人的快乐往往很简单(每天一遍,忘却初恋)
死党一直暗恋校花,但是校花对他印象也不差,就是死党一直太怂了,不敢去找校花,直到昨天看到校花登上了校董儿子的豪车,死党终于彻底死心,大醉一场,作为他的兄弟,我怎么能看他郁郁不振呢?
为了让他忘掉校花,走出阴影,我于是决定把我新收藏的网站分享给他,顺便分享给大家,纯纯的交流技术,大家备好纸巾,不对,备好纸笔????
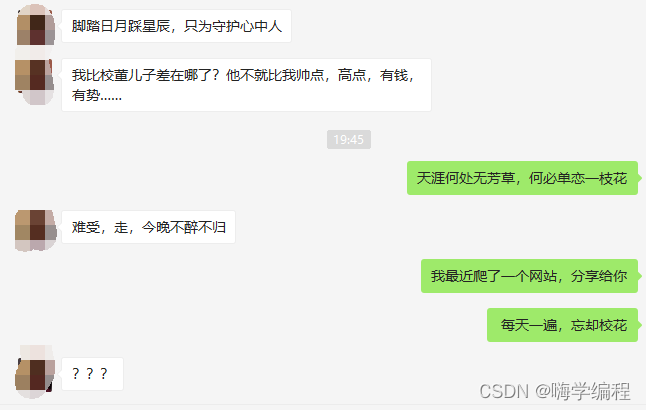
效果如下


爬取目标
网址:(实在是不敢放,满满的求生欲,官方大佬手下留情)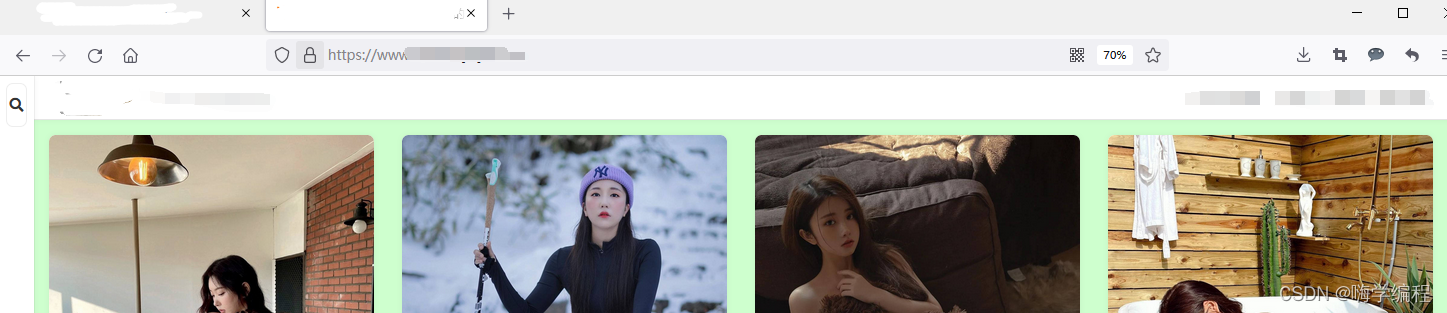
兄弟们啊,不要怪我,不打码不行啊,我是来交流技术的。
要用的工具
软件:
python 3.8 pycharm 2021专业版
模块:
requests
parsel
没有模块 pip 安装模块即可
流程解析
我们首先就是先进入到这个网址,向网站发送网络请求。
然后去拿到它的网页源代码数据,右键点击,查看他的网页源代码。
我们访问网站拿到的数据就是它。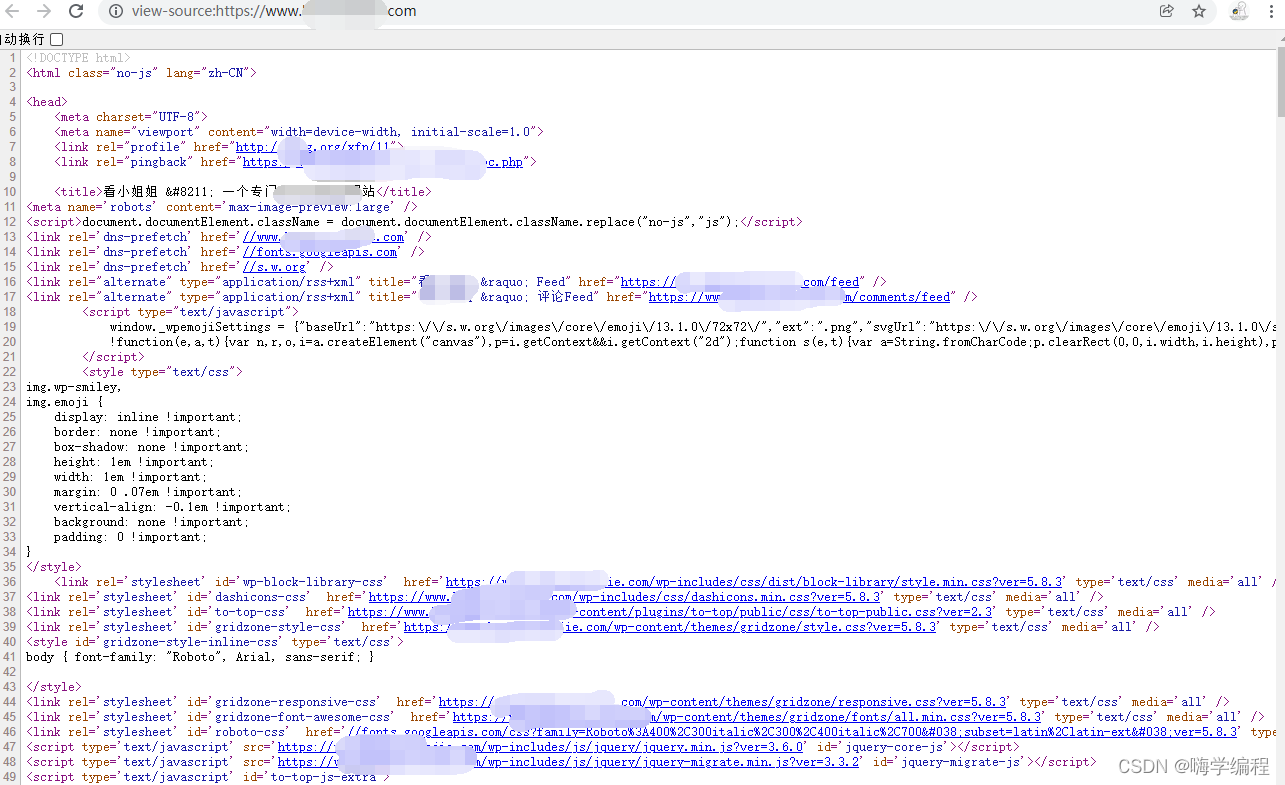
后续的步骤我就不截图了,可以看我视频讲解。
获取到数据后,我们要去解析数据,筛选我们想要的内容,相册详情页地址,标题等等。
然后向详情页发送请求并解析数据,再向图片链接发送请求,获取图片二进制数据,最后保存图片。
详细步骤我都在视频里讲了,大家可以在这里看视频讲解,还有多线程版本
实现代码
import requests import parsel import re import os for page in range(1, 11 ): print (f ' ==================正在爬取第{page}页================== ' ) # 1.向目标网站发送请求(get,post) response = requests.get(f ' https://www.网站不提供,想用来实践技术的话可以私我拿.com/page/{page} ' ) # 2. 获取数据(网页源代码) data_html = response.text # 3. 解析网页(re正则表达式,css选择器,xpath,bs4,json) 提取每一个详情页的链接与标题 zip_data = re.findall( ' <a href="(.*?)" target="_blank"rel="bookmark">(.*?)</a> ' , data_html) for url, title in zip_data: print (f ' ----------------正在爬取{title}---------------- ' ) if not os.path.exists( ' img/ ' + title):
os.mkdir( ' img/ ' + title) # 4. 向详情页发送请求 resp = requests.get(url) # 5. 获取数据(网页源代码) url_data = resp.text # 6. 解析网页 (提取图片链接) selector = parsel.Selector(url_data)
img_list = selector.css( ' p>img::attr(src) ' ).getall() for img in img_list: # 7. 向图片链接发送请求 # 8. 获取数据(图片二进制数据) img_data = requests.get(img).content # 9. 保存数据 img_name = img.split( ' / ' )[-1 ]
with open(f " img/{title}/{img_name} " , mode= ' wb ' ) as f:
f.write(img_data) print (img_name, ' 爬取成功!!! ' ) print (title, ' 爬取成功!!! ' )
# 兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。 # 那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码! # 还会有大佬解答! # 都在这个群里了 924040232 # 欢迎加入,一起讨论 一起学习!
暗恋单恋都不可靠,还是要胆大脸皮厚,主动一点到手了才有结果,不然女朋友都是别人的了,祝大家有情人终成眷属,没有的2022年那必有!
欢迎大家一起在评论中讨论技术,编程嘛,不能一味死板,要灵活有趣才有动力,不低俗不违法,一起进步!